





作者 | Bright Liao
在《程序员眼中的 ChatGPT》一文中,我们聊到了开发人员对于ChatGPT的认知。本文来聊一聊ChatGPT用到的机器学习技术。

机器学习技术的发展
要聊ChatGPT用到的机器学习技术,我们不得不回顾一下机器学习技术的发展。因为,ChatGPT用到的技术不是完全从零的发明,它也是站在巨人的肩膀上发展起来的。
1.机器学习技术的分类
实际上机器学习技术可以追溯到上个世纪三四十年代,一开始就与统计学分不开。早在1936年,著名的统计学家Fisher发明了线性判别分析方法(LDA)。LDA利用方差分析的思想,试图将高维数据分开。这后来演化为一类基础的机器学习技术要解决的问题,即分类问题。
在计算机出现之后,大量的基于计算机的机器学习算法出现,比如决策树、SVM、随机森林、朴素贝叶斯、逻辑回归等。它们也都可以用于解决分类问题。
分类问题是指我们事先知道要分为哪几类,这些类通常是人为定义的。比如人分为男性和女性,编程语言分为C/C++/Java等。
还有一类问题是我们无法预先知道要分为几类的,比如给定一系列的新闻,按照主题进行分组,而我们可能无法事先人为确定有几个主题。此时可以利用机器学习算法自动去发现新闻中有几个类,然后再把不同的新闻放到不同的分类。这种问题是聚类问题。
有时,这个分类可能是连续的,比如,我们要用一个机器学习模型去预测某个人的身高,此时可以认为结果是在某一个范围内连续变化的值。这类问题,我们把它叫做回归问题。与分类的问题的区别仅仅在于我们希望输出一个连续的值。
除此之外,一些典型的机器学习问题还包括:降维、强化学习(通过智能体与环境的交互来学习最佳行动策略)等。
除了根据问题不同进行分类,还可以从机器学习技术使用数据的方式进行分类。从这个角度可以将机器学习技术分为有监督学习、无监督学习、半监督学习等。有监督学习要求我们为模型准备好标签值。无监督学习则无需我们准备标签值,只需数据即可开始训练。半监督学习是指需要一部分有标签值的数据。
从解决的问题上来看,ChatGPT可以认为是一个分类模型,它根据输入的文本预测下一个要输出的词是什么,而词的范围是确定的,即模型的输出是一个确定的分类。
从ChatGPT使用数据的方式来看,可以认为是使用了大量的无监督数据,加上少量的有监督的数据。所以,可以认为ChatGPT是一个半监督的机器学习技术。
2.传统的机器学习算法与基于人工神经网络的机器学习算法
上面提到的决策树、SVM、随机森林、朴素贝叶斯、逻辑回归等算法,多是基于可验证的可理解的统计学知识设计的算法。它们的局限性主要在于效果比较有限,即便使用海量数据也无法继续提升,这要归因于这些模型都是相对简单的模型。由于这些算法都是很早就被开发出来了,并且一直很稳定,没有什么更新,我们一般称这些算法为传统的机器学习算法。
另一类机器学习算法是基于人工神经网络的机器学习算法。这一类算法试图模拟人类的神经网络结构。其起源也很早,要追溯到1943年,W. S. McCulloch和W. Pitts提出的M-P模型。该模型根据生物神经元的结构和工作机理构造了一个简化的数学模型,如下图。
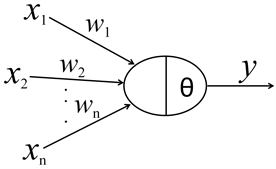
其中,xi代表神经元的第i个输入,权值wi为输入xi对神经元不同突触强度的表征,θ代表神经元的兴奋阀值,y表示神经元的输出,其值的正和负,分别代表神经元的兴奋和抑制。
该模型的数学公式可以表示为:

