





在一项最新的研究中,来自 UW 和 Meta 的研究者提出了一种新的解码算法,将 AlphaGo 采用的蒙特卡洛树搜索算法(Monte-Carlo Tree Search, MCTS)应用到经过近端策略优化(Proximal Policy Optimization, PPO)训练的 RLHF 语言模型上,大幅提高了模型生成文本的质量。

PPO-MCTS 算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过 PPO-MCTS 生成的文本能更好满足任务要求。

论文链接:https://arxiv.org/pdf/2309.15028.pdf
面向大众用户发布的 LLM,如 GPT-4/Claude/LLaMA-2-chat,通常使用 RLHF 以向用户的偏好对齐。PPO 已经成为上述模型进行 RLHF 的首选算法,然而在模型部署时,人们往往采用简单的解码算法(例如 top-p 采样)从这些模型生成文本。
本文的作者提出采用一种蒙特卡洛树搜索算法(MCTS)的变体从 PPO 模型中进行解码,并将该方法命名为 PPO-MCTS。该方法依赖于一个价值模型(value model)来指导最优序列的搜索。因为 PPO 本身即是一种演员 - 评论家算法(actor-critic),故而会在训练中产生一个价值模型作为其副产品。
PPO-MCTS 提出利用这个价值模型指导 MCTS 搜索,并通过理论和实验的角度验证了其效用。作者呼吁使用 RLHF 训练模型的研究者和工程人员保存并开源他们的价值模型。
PPO-MCTS 解码算法
为生成一个 token,PPO-MCTS 会执行若干回合的模拟,并逐步构建一棵搜索树。树的节点代表已生成的文本前缀(包括原 prompt),树的边代表新生成的 token。PPO-MCTS 维护一系列树上的统计值:对于每个节点 s,维护一个访问量 和一个平均价值
和一个平均价值 ;对于每条边
;对于每条边 ,维护一个 Q 值
,维护一个 Q 值 。
。
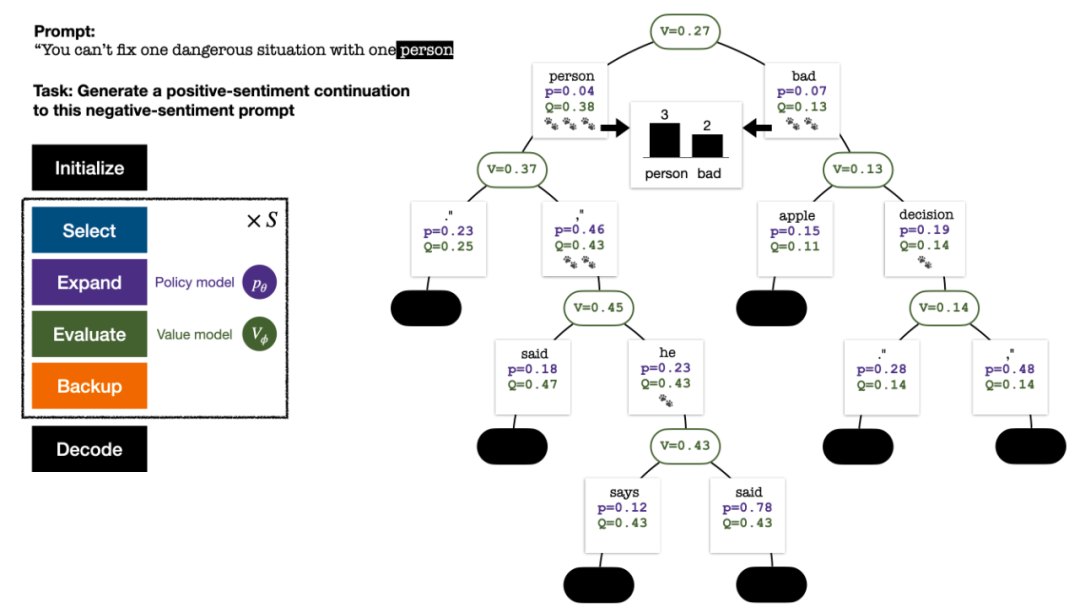
五回合模拟结束时的搜索树。边上



