





首先需要搞明白,为什么需要交叉验证?
交叉验证是机器学习和统计学中常用的一种技术,用于评估预测模型的性能和泛化能力,特别是在数据有限或评估模型对新的未见数据的泛化能力时,交叉验证非常有价值。

那么具体在什么情况下会使用交叉验证呢?
- 模型性能评估:交叉验证有助于估计模型在未见数据上的表现。通过在多个数据子集上训练和评估模型,交叉验证提供了比单一训练-测试分割更稳健的模型性能估计。
- 数据效率:在数据有限的情况下,交叉验证充分利用了所有可用样本,通过同时使用所有数据进行训练和评估,提供了对模型性能更可靠的评估。
- 超参数调优:交叉验证通常用于选择模型的最佳超参数。通过在不同数据子集上使用不同的超参数设置来评估模型的性能,可以确定在整体性能上表现最好的超参数值。
- 检测过拟合:交叉验证有助于检测模型是否对训练数据过拟合。如果模型在训练集上的表现明显优于验证集,可能表明存在过拟合的情况,需要进行调整,如正则化或选择更简单的模型。
- 泛化能力评估:交叉验证提供了对模型对未见数据的泛化能力的评估。通过在多个数据分割上评估模型,它有助于评估模型捕捉数据中的潜在模式的能力,而不依赖于随机性或特定的训练-测试分割。
交叉验证的大致思想可如图5折交叉所示,在每次迭代中,新模型在四个子数据集上训练,并在最后一个保留的子数据集上进行测试,确保所有数据得到利用。通过平均分数及标准差等指标,提供了对模型性能的真实度量
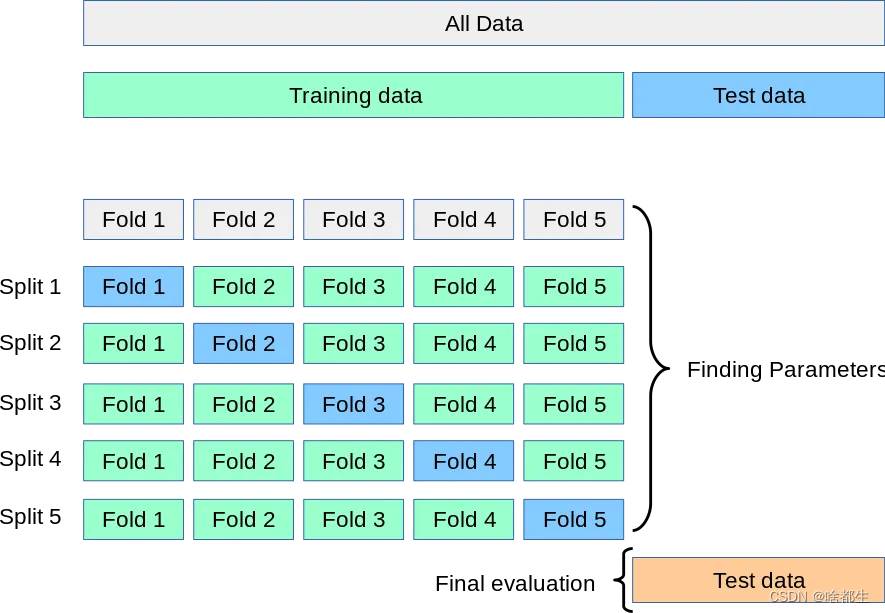
一切还得从K折交叉开始。
KFold
K折交叉在Sklearn中已经集成,此处以7折为例:
from sklearn.datasets import make_regression
from sklearn.model_selection import KFold
x, y = make_regression(n_samples=100)
# Init the splitter
cross_validation = KFold(n_splits=7)分享说明:转发分享请注明出处。


